OOM Developer Guide

ONAP consists of a large number of components, each of which are substantial projects within themselves, which results in a high degree of complexity in deployment and management. To cope with this complexity the ONAP Operations Manager (OOM) uses a Helm model of ONAP - Helm being the primary management system for Kubernetes container systems - to drive all user driven life-cycle management operations. The Helm model of ONAP is composed of a set of hierarchical Helm charts that define the structure of the ONAP components and the configuration of these components. These charts are fully parameterized such that a single environment file defines all of the parameters needed to deploy ONAP. A user of ONAP may maintain several such environment files to control the deployment of ONAP in multiple environments such as development, pre-production, and production.
The following sections describe how the ONAP Helm charts are constructed.
Container Background
Linux containers allow for an application and all of its operating system dependencies to be packaged and deployed as a single unit without including a guest operating system as done with virtual machines. The most popular container solution is Docker which provides tools for container management like the Docker Host (dockerd) which can create, run, stop, move, or delete a container. Docker has a very popular registry of containers images that can be used by any Docker system; however, in the ONAP context, Docker images are built by the standard CI/CD flow and stored in Nexus repositories. OOM uses the “standard” ONAP docker containers and three new ones specifically created for OOM.
Containers are isolated from each other primarily via name spaces within the Linux kernel without the need for multiple guest operating systems. As such, multiple containers can be deployed with little overhead such as all of ONAP can be deployed on a single host. With some optimization of the ONAP components (e.g. elimination of redundant database instances) it may be possible to deploy ONAP on a single laptop computer.
Helm Charts
A Helm chart is a collection of files that describe a related set of Kubernetes resources. A simple chart might be used to deploy something simple, like a memcached pod, while a complex chart might contain many micro-service arranged in a hierarchy as found in the aai ONAP component.
Charts are created as files laid out in a particular directory tree, then they can be packaged into versioned archives to be deployed. There is a public archive of Helm Charts on GitHub that includes many technologies applicable to ONAP. Some of these charts have been used in ONAP and all of the ONAP charts have been created following the guidelines provided.
The top level of the ONAP charts is shown below:
common
├── cassandra
│ ├── Chart.yaml
│ ├── requirements.yaml
│ ├── resources
│ │ ├── config
│ │ │ └── docker-entrypoint.sh
│ │ ├── exec.py
│ │ └── restore.sh
│ ├── templates
│ │ ├── backup
│ │ │ ├── configmap.yaml
│ │ │ ├── cronjob.yaml
│ │ │ ├── pv.yaml
│ │ │ └── pvc.yaml
│ │ ├── configmap.yaml
│ │ ├── pv.yaml
│ │ ├── service.yaml
│ │ └── statefulset.yaml
│ └── values.yaml
├── common
│ ├── Chart.yaml
│ ├── templates
│ │ ├── _createPassword.tpl
│ │ ├── _ingress.tpl
│ │ ├── _labels.tpl
│ │ ├── _mariadb.tpl
│ │ ├── _name.tpl
│ │ ├── _namespace.tpl
│ │ ├── _repository.tpl
│ │ ├── _resources.tpl
│ │ ├── _secret.yaml
│ │ ├── _service.tpl
│ │ ├── _storage.tpl
│ │ └── _tplValue.tpl
│ └── values.yaml
├── ...
└── postgres-legacy
├── Chart.yaml
├── requirements.yaml
├── charts
└── configs
The common section of charts consists of a set of templates that assist with parameter substitution (_name.tpl, _namespace.tpl and others) and a set of charts for components used throughout ONAP. When the common components are used by other charts they are instantiated each time or we can deploy a shared instances for several components.
All of the ONAP components have charts that follow the pattern shown below:
name-of-my-component
├── Chart.yaml
├── requirements.yaml
├── component
│ └── subcomponent-folder
├── charts
│ └── subchart-folder
├── resources
│ ├── folder1
│ │ ├── file1
│ │ └── file2
│ └── folder1
│ ├── file3
│ └── folder3
│ └── file4
├── templates
│ ├── NOTES.txt
│ ├── configmap.yaml
│ ├── deployment.yaml
│ ├── ingress.yaml
│ ├── job.yaml
│ ├── secrets.yaml
│ └── service.yaml
└── values.yaml
Note that the component charts / components may include a hierarchy of sub components and in themselves can be quite complex.
You can use either charts or components folder for your subcomponents. charts folder means that the subcomponent will always been deployed.
components folders means we can choose if we want to deploy the subcomponent.
This choice is done in root values.yaml:
---
global:
key: value
component1:
enabled: true
component2:
enabled: true
Then in requirements.yaml, you’ll use these values:
---
dependencies:
- name: common
version: ~x.y-0
repository: '@local'
- name: component1
version: ~x.y-0
repository: 'file://components/component1'
condition: component1.enabled
- name: component2
version: ~x.y-0
repository: 'file://components/component2'
condition: component2.enabled
Configuration of the components varies somewhat from component to component but generally follows the pattern of one or more configmap.yaml files which can directly provide configuration to the containers in addition to processing configuration files stored in the config directory. It is the responsibility of each ONAP component team to update these configuration files when changes are made to the project containers that impact configuration.
The following section describes how the hierarchical ONAP configuration system is key to management of such a large system.
Configuration Management
ONAP is a large system composed of many components - each of which are complex systems in themselves - that needs to be deployed in a number of different ways. For example, within a single operator’s network there may be R&D deployments under active development, pre-production versions undergoing system testing and production systems that are operating live networks. Each of these deployments will differ in significant ways, such as the version of the software images deployed. In addition, there may be a number of application specific configuration differences, such as operating system environment variables. The following describes how the Helm configuration management system is used within the OOM project to manage both ONAP infrastructure configuration as well as ONAP components configuration.
One of the artifacts that OOM/Kubernetes uses to deploy ONAP components is the deployment specification, yet another yaml file. Within these deployment specs are a number of parameters as shown in the following example:
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: zookeeper
helm.sh/chart: zookeeper
app.kubernetes.io/component: server
app.kubernetes.io/managed-by: Tiller
app.kubernetes.io/instance: onap-oof
name: onap-oof-zookeeper
namespace: onap
spec:
<...>
replicas: 3
selector:
matchLabels:
app.kubernetes.io/name: zookeeper
app.kubernetes.io/component: server
app.kubernetes.io/instance: onap-oof
serviceName: onap-oof-zookeeper-headless
template:
metadata:
labels:
app.kubernetes.io/name: zookeeper
helm.sh/chart: zookeeper
app.kubernetes.io/component: server
app.kubernetes.io/managed-by: Tiller
app.kubernetes.io/instance: onap-oof
spec:
<...>
affinity:
containers:
- name: zookeeper
<...>
image: gcr.io/google_samples/k8szk:v3
imagePullPolicy: Always
<...>
ports:
- containerPort: 2181
name: client
protocol: TCP
- containerPort: 3888
name: election
protocol: TCP
- containerPort: 2888
name: server
protocol: TCP
<...>
Note that within the statefulset specification, one of the container arguments is the key/value pair image: gcr.io/google_samples/k8szk:v3 which specifies the version of the zookeeper software to deploy. Although the statefulset specifications greatly simplify statefulset, maintenance of the statefulset specifications themselves become problematic as software versions change over time or as different versions are required for different statefulsets. For example, if the R&D team needs to deploy a newer version of mariadb than what is currently used in the production environment, they would need to clone the statefulset specification and change this value. Fortunately, this problem has been solved with the templating capabilities of Helm.
The following example shows how the statefulset specifications are modified to incorporate Helm templates such that key/value pairs can be defined outside of the statefulset specifications and passed during instantiation of the component.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: {{ include "common.fullname" . }}
namespace: {{ include "common.namespace" . }}
labels: {{- include "common.labels" . | nindent 4 }}
spec:
replicas: {{ .Values.replicaCount }}
selector:
matchLabels: {{- include "common.matchLabels" . | nindent 6 }}
# serviceName is only needed for StatefulSet
# put the postfix part only if you have add a postfix on the service name
serviceName: {{ include "common.servicename" . }}-{{ .Values.service.postfix }}
<...>
template:
metadata:
labels: {{- include "common.labels" . | nindent 8 }}
annotations: {{- include "common.tplValue" (dict "value" .Values.podAnnotations "context" $) | nindent 8 }}
name: {{ include "common.name" . }}
spec:
<...>
containers:
- name: {{ include "common.name" . }}
image: {{ .Values.image }}
imagePullPolicy: {{ .Values.global.pullPolicy | default .Values.pullPolicy }}
ports:
{{- range $index, $port := .Values.service.ports }}
- containerPort: {{ $port.port }}
name: {{ $port.name }}
{{- end }}
{{- range $index, $port := .Values.service.headlessPorts }}
- containerPort: {{ $port.port }}
name: {{ $port.name }}
{{- end }}
<...>
This version of the statefulset specification has gone through the process of templating values that are likely to change between statefulsets. Note that the image is now specified as: image: {{ .Values.image }} instead of a string used previously. During the statefulset phase, Helm (actually the Helm sub-component Tiller) substitutes the {{ .. }} entries with a variable defined in a values.yaml file. The content of this file is as follows:
<...>
image: gcr.io/google_samples/k8szk:v3
replicaCount: 3
<...>
Within the values.yaml file there is an image key with the value gcr.io/google_samples/k8szk:v3 which is the same value used in the non-templated version. Once all of the substitutions are complete, the resulting statefulset specification ready to be used by Kubernetes.
When creating a template consider the use of default values if appropriate. Helm templating has built in support for DEFAULT values, here is an example:
imagePullSecrets:
- name: "{{ .Values.nsPrefix | default "onap" }}-docker-registry-key"
The pipeline operator (“|”) used here hints at that power of Helm templates in that much like an operating system command line the pipeline operator allow over 60 Helm functions to be embedded directly into the template (note that the Helm template language is a superset of the Go template language). These functions include simple string operations like upper and more complex flow control operations like if/else.
OOM is mainly helm templating. In order to have consistent deployment of the different components of ONAP, some rules must be followed.
Templates are provided in order to create Kubernetes resources (Secrets, Ingress, Services, …) or part of Kubernetes resources (names, labels, resources requests and limits, …).
a full list and simple description is done in kubernetes/common/common/documentation.rst.
Service template
In order to create a Service for a component, you have to create a file (with service in the name. For normal service, just put the following line:
{{ include "common.service" . }}
For headless service, the line to put is the following:
{{ include "common.headlessService" . }}
The configuration of the service is done in component values.yaml:
service:
name: NAME-OF-THE-SERVICE
postfix: MY-POSTFIX
type: NodePort
annotations:
someAnnotationsKey: value
ports:
- name: tcp-MyPort
port: 5432
nodePort: 88
- name: http-api
port: 8080
nodePort: 89
- name: https-api
port: 9443
nodePort: 90
annotations and postfix keys are optional. if service.type is NodePort, then you have to give nodePort value for your service ports (which is the end of the computed nodePort, see example).
It would render the following Service Resource (for a component named name-of-my-component, with version x.y.z, helm deployment name my-deployment and global.nodePortPrefix 302):
apiVersion: v1
kind: Service
metadata:
annotations:
someAnnotationsKey: value
name: NAME-OF-THE-SERVICE-MY-POSTFIX
labels:
app.kubernetes.io/name: name-of-my-component
helm.sh/chart: name-of-my-component-x.y.z
app.kubernetes.io/instance: my-deployment-name-of-my-component
app.kubernetes.io/managed-by: Tiller
spec:
ports:
- port: 5432
targetPort: tcp-MyPort
nodePort: 30288
- port: 8080
targetPort: http-api
nodePort: 30289
- port: 9443
targetPort: https-api
nodePort: 30290
selector:
app.kubernetes.io/name: name-of-my-component
app.kubernetes.io/instance: my-deployment-name-of-my-component
type: NodePort
In the deployment or statefulSet file, you needs to set the good labels in order for the service to match the pods.
here’s an example to be sure it matches (for a statefulSet):
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: {{ include "common.fullname" . }}
namespace: {{ include "common.namespace" . }}
labels: {{- include "common.labels" . | nindent 4 }}
spec:
selector:
matchLabels: {{- include "common.matchLabels" . | nindent 6 }}
# serviceName is only needed for StatefulSet
# put the postfix part only if you have add a postfix on the service name
serviceName: {{ include "common.servicename" . }}-{{ .Values.service.postfix }}
<...>
template:
metadata:
labels: {{- include "common.labels" . | nindent 8 }}
annotations: {{- include "common.tplValue" (dict "value" .Values.podAnnotations "context" $) | nindent 8 }}
name: {{ include "common.name" . }}
spec:
<...>
containers:
- name: {{ include "common.name" . }}
ports:
{{- range $index, $port := .Values.service.ports }}
- containerPort: {{ $port.port }}
name: {{ $port.name }}
{{- end }}
{{- range $index, $port := .Values.service.headlessPorts }}
- containerPort: {{ $port.port }}
name: {{ $port.name }}
{{- end }}
<...>
The configuration of the service is done in component values.yaml:
service:
name: NAME-OF-THE-SERVICE
headless:
postfix: NONE
annotations:
anotherAnnotationsKey : value
publishNotReadyAddresses: true
headlessPorts:
- name: tcp-MyPort
port: 5432
- name: http-api
port: 8080
- name: https-api
port: 9443
headless.annotations, headless.postfix and headless.publishNotReadyAddresses keys are optional.
If headless.postfix is not set, then we’ll add -headless at the end of the service name.
If it set to NONE, there will be not postfix.
And if set to something, it will add -something at the end of the service name.
It would render the following Service Resource (for a component named name-of-my-component, with version x.y.z, helm deployment name my-deployment and global.nodePortPrefix 302):
apiVersion: v1
kind: Service
metadata:
annotations:
anotherAnnotationsKey: value
name: NAME-OF-THE-SERVICE
labels:
app.kubernetes.io/name: name-of-my-component
helm.sh/chart: name-of-my-component-x.y.z
app.kubernetes.io/instance: my-deployment-name-of-my-component
app.kubernetes.io/managed-by: Tiller
spec:
clusterIP: None
ports:
- port: 5432
targetPort: tcp-MyPort
nodePort: 30288
- port: 8080
targetPort: http-api
nodePort: 30289
- port: 9443
targetPort: https-api
nodePort: 30290
publishNotReadyAddresses: true
selector:
app.kubernetes.io/name: name-of-my-component
app.kubernetes.io/instance: my-deployment-name-of-my-component
type: ClusterIP
Previous example of StatefulSet would also match (except for the postfix part obviously).
Creating Deployment or StatefulSet
Deployment and StatefulSet should use the apps/v1 (which has appeared in v1.9). As seen on the service part, the following parts are mandatory:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: {{ include "common.fullname" . }}
namespace: {{ include "common.namespace" . }}
labels: {{- include "common.labels" . | nindent 4 }}
spec:
selector:
matchLabels: {{- include "common.matchLabels" . | nindent 6 }}
# serviceName is only needed for StatefulSet
# put the postfix part only if you have add a postfix on the service name
serviceName: {{ include "common.servicename" . }}-{{ .Values.service.postfix }}
<...>
template:
metadata:
labels: {{- include "common.labels" . | nindent 8 }}
annotations: {{- include "common.tplValue" (dict "value" .Values.podAnnotations "context" $) | nindent 8 }}
name: {{ include "common.name" . }}
spec:
<...>
containers:
- name: {{ include "common.name" . }}
ONAP Application Configuration
Dependency Management
These Helm charts describe the desired state of an ONAP deployment and instruct the Kubernetes container manager as to how to maintain the deployment in this state. These dependencies dictate the order in-which the containers are started for the first time such that such dependencies are always met without arbitrary sleep times between container startups. For example, the SDC back-end container requires the Elastic-Search, Cassandra and Kibana containers within SDC to be ready and is also dependent on DMaaP (or the message-router) to be ready - where ready implies the built-in “readiness” probes succeeded - before becoming fully operational. When an initial deployment of ONAP is requested the current state of the system is NULL so ONAP is deployed by the Kubernetes manager as a set of Docker containers on one or more predetermined hosts. The hosts could be physical machines or virtual machines. When deploying on virtual machines the resulting system will be very similar to “Heat” based deployments, i.e. Docker containers running within a set of VMs, the primary difference being that the allocation of containers to VMs is done dynamically with OOM and statically with “Heat”. Example SO deployment descriptor file shows SO’s dependency on its mariadb data-base component:
SO deployment specification excerpt:
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "common.fullname" . }}
namespace: {{ include "common.namespace" . }}
labels: {{- include "common.labels" . | nindent 4 }}
spec:
replicas: {{ .Values.replicaCount }}
selector:
matchLabels: {{- include "common.matchLabels" . | nindent 6 }}
template:
metadata:
labels:
app: {{ include "common.name" . }}
release: {{ .Release.Name }}
spec:
initContainers:
- command:
- /app/ready.py
args:
- --container-name
- so-mariadb
env:
...
Kubernetes Container Orchestration
The ONAP components are managed by the Kubernetes container management system which maintains the desired state of the container system as described by one or more deployment descriptors - similar in concept to OpenStack HEAT Orchestration Templates. The following sections describe the fundamental objects managed by Kubernetes, the network these components use to communicate with each other and other entities outside of ONAP and the templates that describe the configuration and desired state of the ONAP components.
Name Spaces
Within the namespaces are Kubernetes services that provide external connectivity to pods that host Docker containers.
ONAP Components to Kubernetes Object Relationships
Kubernetes deployments consist of multiple objects:
nodes - a worker machine - either physical or virtual - that hosts multiple containers managed by Kubernetes.
services - an abstraction of a logical set of pods that provide a micro-service.
pods - one or more (but typically one) container(s) that provide specific application functionality.
persistent volumes - One or more permanent volumes need to be established to hold non-ephemeral configuration and state data.
The relationship between these objects is shown in the following figure:
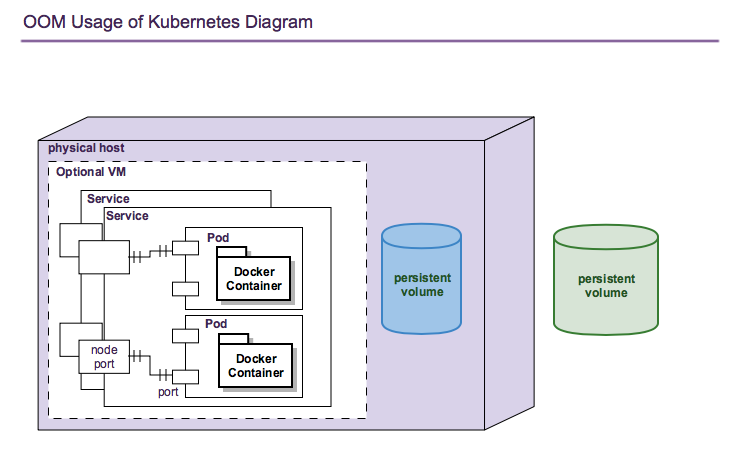
OOM uses these Kubernetes objects as described in the following sections.
Nodes
OOM works with both physical and virtual worker machines.
Virtual Machine Deployments - If ONAP is to be deployed onto a set of virtual machines, the creation of the VMs is outside of the scope of OOM and could be done in many ways, such as
manually, for example by a user using the OpenStack Horizon dashboard or AWS EC2, or
automatically, for example with the use of a OpenStack Heat Orchestration Template which builds an ONAP stack, Azure ARM template, AWS CloudFormation Template, or
orchestrated, for example with Cloudify creating the VMs from a TOSCA template and controlling their life cycle for the life of the ONAP deployment.
Physical Machine Deployments - If ONAP is to be deployed onto physical machines there are several options but the recommendation is to use Rancher along with Helm to associate hosts with a Kubernetes cluster.
Pods
A group of containers with shared storage and networking can be grouped together into a Kubernetes pod. All of the containers within a pod are co-located and co-scheduled so they operate as a single unit. Within ONAP Amsterdam release, pods are mapped one-to-one to docker containers although this may change in the future. As explained in the Services section below the use of Pods within each ONAP component is abstracted from other ONAP components.
Services
OOM uses the Kubernetes service abstraction to provide a consistent access point for each of the ONAP components independent of the pod or container architecture of that component. For example, the SDNC component may introduce OpenDaylight clustering as some point and change the number of pods in this component to three or more but this change will be isolated from the other ONAP components by the service abstraction. A service can include a load balancer on its ingress to distribute traffic between the pods and even react to dynamic changes in the number of pods if they are part of a replica set.
Persistent Volumes
To enable ONAP to be deployed into a wide variety of cloud infrastructures a flexible persistent storage architecture, built on Kubernetes persistent volumes, provides the ability to define the physical storage in a central location and have all ONAP components securely store their data.
When deploying ONAP into a public cloud, available storage services such as AWS Elastic Block Store, Azure File, or GCE Persistent Disk are options. Alternatively, when deploying into a private cloud the storage architecture might consist of Fiber Channel, Gluster FS, or iSCSI. Many other storage options existing, refer to the Kubernetes Storage Class documentation for a full list of the options. The storage architecture may vary from deployment to deployment but in all cases a reliable, redundant storage system must be provided to ONAP with which the state information of all ONAP components will be securely stored. The Storage Class for a given deployment is a single parameter listed in the ONAP values.yaml file and therefore is easily customized. Operation of this storage system is outside the scope of the OOM.
Insert values.yaml code block with storage block here
Once the storage class is selected and the physical storage is provided, the ONAP deployment step creates a pool of persistent volumes within the given physical storage that is used by all of the ONAP components. ONAP components simply make a claim on these persistent volumes (PV), with a persistent volume claim (PVC), to gain access to their storage.
The following figure illustrates the relationships between the persistent volume claims, the persistent volumes, the storage class, and the physical storage.
![digraph PV {
label = "Persistance Volume Claim to Physical Storage Mapping"
{
node [shape=cylinder]
D0 [label="Drive0"]
D1 [label="Drive1"]
Dx [label="Drivex"]
}
{
node [shape=Mrecord label="StorageClass:ceph"]
sc
}
{
node [shape=point]
p0 p1 p2
p3 p4 p5
}
subgraph clusterSDC {
label="SDC"
PVC0
PVC1
}
subgraph clusterSDNC {
label="SDNC"
PVC2
}
subgraph clusterSO {
label="SO"
PVCn
}
PV0 -> sc
PV1 -> sc
PV2 -> sc
PVn -> sc
sc -> {D0 D1 Dx}
PVC0 -> PV0
PVC1 -> PV1
PVC2 -> PV2
PVCn -> PVn
# force all of these nodes to the same line in the given order
subgraph {
rank = same; PV0;PV1;PV2;PVn;p0;p1;p2
PV0->PV1->PV2->p0->p1->p2->PVn [style=invis]
}
subgraph {
rank = same; D0;D1;Dx;p3;p4;p5
D0->D1->p3->p4->p5->Dx [style=invis]
}
}](_images/graphviz-4e97a41d71fc1fe0d185775125e3f656015af324.png)
In-order for an ONAP component to use a persistent volume it must make a claim against a specific persistent volume defined in the ONAP common charts. Note that there is a one-to-one relationship between a PVC and PV. The following is an excerpt from a component chart that defines a PVC:
Insert PVC example here
OOM Networking with Kubernetes
DNS
Ports - Flattening the containers also expose port conflicts between the containers which need to be resolved.
Node Ports
Pod Placement Rules
OOM will use the rich set of Kubernetes node and pod affinity / anti-affinity rules to minimize the chance of a single failure resulting in a loss of ONAP service. Node affinity / anti-affinity is used to guide the Kubernetes orchestrator in the placement of pods on nodes (physical or virtual machines). For example:
if a container used Intel DPDK technology the pod may state that it as affinity to an Intel processor based node, or
geographical based node labels (such as the Kubernetes standard zone or region labels) may be used to ensure placement of a DCAE complex close to the VNFs generating high volumes of traffic thus minimizing networking cost. Specifically, if nodes were pre-assigned labels East and West, the pod deployment spec to distribute pods to these nodes would be:
nodeSelector:
failure-domain.beta.Kubernetes.io/region: {{ .Values.location }}
“location: West” is specified in the values.yaml file used to deploy one DCAE cluster and “location: East” is specified in a second values.yaml file (see OOM Configuration Management for more information about configuration files like the values.yaml file).
Node affinity can also be used to achieve geographic redundancy if pods are assigned to multiple failure domains. For more information refer to Assigning Pods to Nodes.
Note
One could use Pod to Node assignment to totally constrain Kubernetes when doing initial container assignment to replicate the Amsterdam release OpenStack Heat based deployment. Should one wish to do this, each VM would need a unique node name which would be used to specify a node constaint for every component. These assignment could be specified in an environment specific values.yaml file. Constraining Kubernetes in this way is not recommended.
Kubernetes has a comprehensive system called Taints and Tolerations that can be used to force the container orchestrator to repel pods from nodes based on static events (an administrator assigning a taint to a node) or dynamic events (such as a node becoming unreachable or running out of disk space). There are no plans to use taints or tolerations in the ONAP Beijing release. Pod affinity / anti-affinity is the concept of creating a spacial relationship between pods when the Kubernetes orchestrator does assignment (both initially an in operation) to nodes as explained in Inter-pod affinity and anti-affinity. For example, one might choose to co-located all of the ONAP SDC containers on a single node as they are not critical runtime components and co-location minimizes overhead. On the other hand, one might choose to ensure that all of the containers in an ODL cluster (SDNC and APPC) are placed on separate nodes such that a node failure has minimal impact to the operation of the cluster. An example of how pod affinity / anti-affinity is shown below:
Pod Affinity / Anti-Affinity
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: failure-domain.beta.Kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: Kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: gcr.io/google_containers/pause:2.0
This example contains both podAffinity and podAntiAffinity rules, the first rule is is a must (requiredDuringSchedulingIgnoredDuringExecution) while the second will be met pending other considerations (preferredDuringSchedulingIgnoredDuringExecution). Preemption Another feature that may assist in achieving a repeatable deployment in the presence of faults that may have reduced the capacity of the cloud is assigning priority to the containers such that mission critical components have the ability to evict less critical components. Kubernetes provides this capability with Pod Priority and Preemption. Prior to having more advanced production grade features available, the ability to at least be able to re-deploy ONAP (or a subset of) reliably provides a level of confidence that should an outage occur the system can be brought back on-line predictably.
Health Checks
Monitoring of ONAP components is configured in the agents within JSON files and stored in gerrit under the consul-agent-config, here is an example from the AAI model loader (aai-model-loader-health.json):
{
"service": {
"name": "A&AI Model Loader",
"checks": [
{
"id": "model-loader-process",
"name": "Model Loader Presence",
"script": "/consul/config/scripts/model-loader-script.sh",
"interval": "15s",
"timeout": "1s"
}
]
}
}
Liveness Probes
These liveness probes can simply check that a port is available, that a built-in health check is reporting good health, or that the Consul health check is positive. For example, to monitor the SDNC component has following liveness probe can be found in the SDNC DB deployment specification:
sdnc db liveness probe
livenessProbe:
exec:
command: ["mysqladmin", "ping"]
initialDelaySeconds: 30 periodSeconds: 10
timeoutSeconds: 5
The ‘initialDelaySeconds’ control the period of time between the readiness probe succeeding and the liveness probe starting. ‘periodSeconds’ and ‘timeoutSeconds’ control the actual operation of the probe. Note that containers are inherently ephemeral so the healing action destroys failed containers and any state information within it. To avoid a loss of state, a persistent volume should be used to store all data that needs to be persisted over the re-creation of a container. Persistent volumes have been created for the database components of each of the projects and the same technique can be used for all persistent state information.
Environment Files
MSB Integration
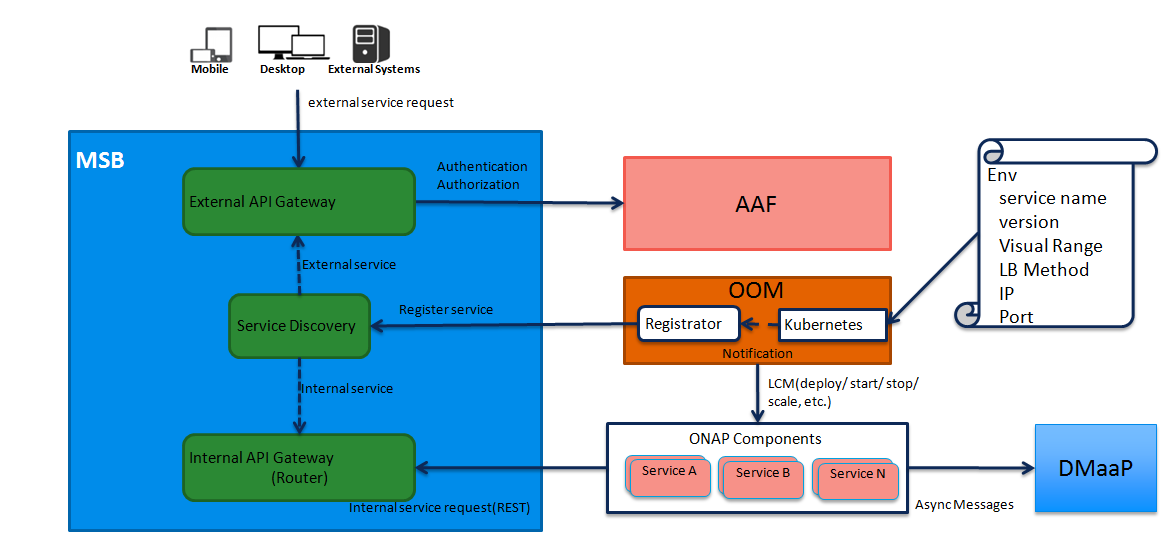
The Microservices Bus Project provides facilities to integrate micro-services into ONAP and therefore needs to integrate into OOM - primarily through Consul which is the backend of MSB service discovery. The following is a brief description of how this integration will be done:
A registrator to push the service endpoint info to MSB service discovery.
The needed service endpoint info is put into the kubernetes yaml file as annotation, including service name, Protocol,version, visual range,LB method, IP, Port,etc.
OOM deploy/start/restart/scale in/scale out/upgrade ONAP components
Registrator watch the kubernetes event
When an ONAP component instance has been started/destroyed by OOM, Registrator get the notification from kubernetes
Registrator parse the service endpoint info from annotation and register/update/unregister it to MSB service discovery
MSB API Gateway uses the service endpoint info for service routing and load balancing.
Details of the registration service API can be found at Microservice Bus API Documentation.
ONAP Component Registration to MSB
The charts of all ONAP components intending to register against MSB must have an annotation in their service(s) template. A sdc example follows:
apiVersion: v1
kind: Service
metadata:
labels:
app: sdc-be
name: sdc-be
namespace: "{{ .Values.nsPrefix }}"
annotations:
msb.onap.org/service-info: '[
{
"serviceName": "sdc",
"version": "v1",
"url": "/sdc/v1",
"protocol": "REST",
"port": "8080",
"visualRange":"1"
},
{
"serviceName": "sdc-deprecated",
"version": "v1",
"url": "/sdc/v1",
"protocol": "REST",
"port": "8080",
"visualRange":"1",
"path":"/sdc/v1"
}
]'
...
MSB Integration with OOM
A preliminary view of the OOM-MSB integration is as follows:
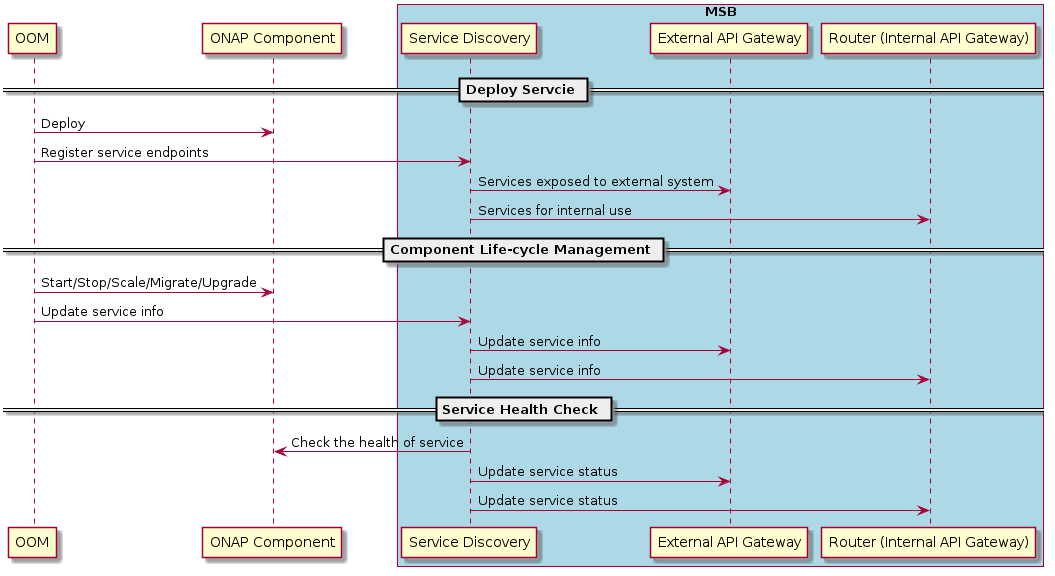
A message sequence chart of the registration process:
MSB Deployment Instructions
MSB is helm installable ONAP component which is often automatically deployed. To install it individually enter:
> helm install <repo-name>/msb
Note
TBD: Vaidate if the following procedure is still required.
Please note that Kubernetes authentication token must be set at kubernetes/kube2msb/values.yaml so the kube2msb registrator can get the access to watch the kubernetes events and get service annotation by Kubernetes APIs. The token can be found in the kubectl configuration file ~/.kube/config
More details can be found here MSB installation.