Kubernetes Container Orchestration
The ONAP components are managed by the Kubernetes container management system which maintains the desired state of the container system as described by one or more deployment descriptors - similar in concept to OpenStack HEAT Orchestration Templates. The following sections describe the fundamental objects managed by Kubernetes, the network these components use to communicate with each other and other entities outside of ONAP and the templates that describe the configuration and desired state of the ONAP components.
Name Spaces
Within the namespaces are Kubernetes services that provide external connectivity to pods that host Docker containers.
ONAP Components to Kubernetes Object Relationships
Kubernetes deployments consist of multiple objects:
nodes - a worker machine - either physical or virtual - that hosts multiple containers managed by Kubernetes.
services - an abstraction of a logical set of pods that provide a micro-service.
pods - one or more (but typically one) container(s) that provide specific application functionality.
persistent volumes - One or more permanent volumes need to be established to hold non-ephemeral configuration and state data.
The relationship between these objects is shown in the following figure:
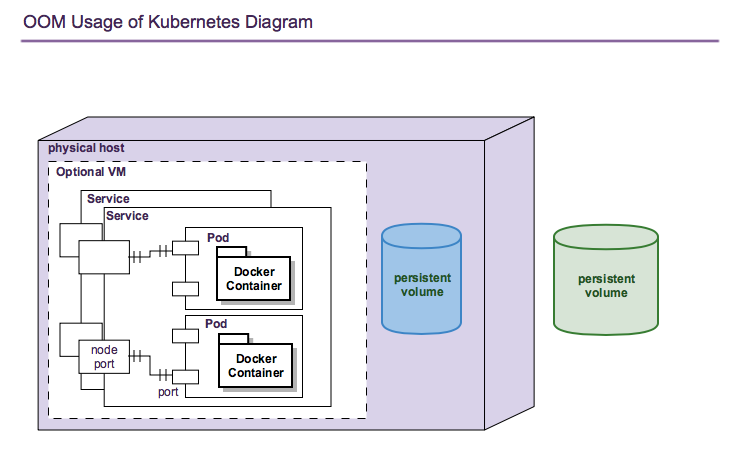
OOM uses these Kubernetes objects as described in the following sections.
Nodes
OOM works with both physical and virtual worker machines.
Virtual Machine Deployments - If ONAP is to be deployed onto a set of virtual machines, the creation of the VMs is outside of the scope of OOM and could be done in many ways, such as
manually, for example by a user using the OpenStack Horizon dashboard or AWS EC2, or
automatically, for example with the use of a OpenStack Heat Orchestration Template which builds an ONAP stack, Azure ARM template, AWS CloudFormation Template, or
orchestrated, for example with Cloudify creating the VMs from a TOSCA template and controlling their life cycle for the life of the ONAP deployment.
Physical Machine Deployments - If ONAP is to be deployed onto physical machines there are several options but the recommendation is to use Rancher along with Helm to associate hosts with a Kubernetes cluster.
Pods
A group of containers with shared storage and networking can be grouped together into a Kubernetes pod. All of the containers within a pod are co-located and co-scheduled so they operate as a single unit. Within ONAP Amsterdam release, pods are mapped one-to-one to docker containers although this may change in the future. As explained in the Services section below the use of Pods within each ONAP component is abstracted from other ONAP components.
Services
OOM uses the Kubernetes service abstraction to provide a consistent access point for each of the ONAP components independent of the pod or container architecture of that component. For example, the SDNC component may introduce OpenDaylight clustering as some point and change the number of pods in this component to three or more but this change will be isolated from the other ONAP components by the service abstraction. A service can include a load balancer on its ingress to distribute traffic between the pods and even react to dynamic changes in the number of pods if they are part of a replica set.
Persistent Volumes
To enable ONAP to be deployed into a wide variety of cloud infrastructures a flexible persistent storage architecture, built on Kubernetes persistent volumes, provides the ability to define the physical storage in a central location and have all ONAP components securely store their data.
When deploying ONAP into a public cloud, available storage services such as AWS Elastic Block Store, Azure File, or GCE Persistent Disk are options. Alternatively, when deploying into a private cloud the storage architecture might consist of Fiber Channel, Gluster FS, or iSCSI. Many other storage options existing, refer to the Kubernetes Storage Class documentation for a full list of the options. The storage architecture may vary from deployment to deployment but in all cases a reliable, redundant storage system must be provided to ONAP with which the state information of all ONAP components will be securely stored. The Storage Class for a given deployment is a single parameter listed in the ONAP values.yaml file and therefore is easily customized. Operation of this storage system is outside the scope of the OOM.
Insert values.yaml code block with storage block here
Once the storage class is selected and the physical storage is provided, the ONAP deployment step creates a pool of persistent volumes within the given physical storage that is used by all of the ONAP components. ONAP components simply make a claim on these persistent volumes (PV), with a persistent volume claim (PVC), to gain access to their storage.
The following figure illustrates the relationships between the persistent volume claims, the persistent volumes, the storage class, and the physical storage.
![digraph PV {
label = "Persistance Volume Claim to Physical Storage Mapping"
{
node [shape=cylinder]
D0 [label="Drive0"]
D1 [label="Drive1"]
Dx [label="Drivex"]
}
{
node [shape=Mrecord label="StorageClass:ceph"]
sc
}
{
node [shape=point]
p0 p1 p2
p3 p4 p5
}
subgraph clusterSDC {
label="SDC"
PVC0
PVC1
}
subgraph clusterSDNC {
label="SDNC"
PVC2
}
subgraph clusterSO {
label="SO"
PVCn
}
PV0 -> sc
PV1 -> sc
PV2 -> sc
PVn -> sc
sc -> {D0 D1 Dx}
PVC0 -> PV0
PVC1 -> PV1
PVC2 -> PV2
PVCn -> PVn
# force all of these nodes to the same line in the given order
subgraph {
rank = same; PV0;PV1;PV2;PVn;p0;p1;p2
PV0->PV1->PV2->p0->p1->p2->PVn [style=invis]
}
subgraph {
rank = same; D0;D1;Dx;p3;p4;p5
D0->D1->p3->p4->p5->Dx [style=invis]
}
}](../../../_images/graphviz-6dc1064e19ab22f7341176133a49c8c82ad55b38.png)
In-order for an ONAP component to use a persistent volume it must make a claim against a specific persistent volume defined in the ONAP common charts. Note that there is a one-to-one relationship between a PVC and PV. The following is an excerpt from a component chart that defines a PVC:
Insert PVC example here
OOM Networking with Kubernetes
DNS
Ports - Flattening the containers also expose port conflicts between the containers which need to be resolved.
Pod Placement Rules
OOM will use the rich set of Kubernetes node and pod affinity / anti-affinity rules to minimize the chance of a single failure resulting in a loss of ONAP service. Node affinity / anti-affinity is used to guide the Kubernetes orchestrator in the placement of pods on nodes (physical or virtual machines). For example:
if a container used Intel DPDK technology the pod may state that it as affinity to an Intel processor based node, or
geographical based node labels (such as the Kubernetes standard zone or region labels) may be used to ensure placement of a DCAE complex close to the VNFs generating high volumes of traffic thus minimizing networking cost. Specifically, if nodes were pre-assigned labels East and West, the pod deployment spec to distribute pods to these nodes would be:
nodeSelector:
failure-domain.beta.Kubernetes.io/region: {{ .Values.location }}
“location: West” is specified in the values.yaml file used to deploy one DCAE cluster and “location: East” is specified in a second values.yaml file (see OOM Configuration Management for more information about configuration files like the values.yaml file).
Node affinity can also be used to achieve geographic redundancy if pods are assigned to multiple failure domains. For more information refer to Assigning Pods to Nodes.
Note
One could use Pod to Node assignment to totally constrain Kubernetes when doing initial container assignment to replicate the Amsterdam release OpenStack Heat based deployment. Should one wish to do this, each VM would need a unique node name which would be used to specify a node constaint for every component. These assignment could be specified in an environment specific values.yaml file. Constraining Kubernetes in this way is not recommended.
Kubernetes has a comprehensive system called Taints and Tolerations that can be used to force the container orchestrator to repel pods from nodes based on static events (an administrator assigning a taint to a node) or dynamic events (such as a node becoming unreachable or running out of disk space). There are no plans to use taints or tolerations in the ONAP Beijing release. Pod affinity / anti-affinity is the concept of creating a spacial relationship between pods when the Kubernetes orchestrator does assignment (both initially an in operation) to nodes as explained in Inter-pod affinity and anti-affinity. For example, one might choose to co-located all of the ONAP SDC containers on a single node as they are not critical runtime components and co-location minimizes overhead. On the other hand, one might choose to ensure that all of the containers in an ODL cluster (SDNC and APPC) are placed on separate nodes such that a node failure has minimal impact to the operation of the cluster. An example of how pod affinity / anti-affinity is shown below:
Pod Affinity / Anti-Affinity
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: failure-domain.beta.Kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: Kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: gcr.io/google_containers/pause:2.0
This example contains both podAffinity and podAntiAffinity rules, the first rule is is a must (requiredDuringSchedulingIgnoredDuringExecution) while the second will be met pending other considerations (preferredDuringSchedulingIgnoredDuringExecution). Preemption Another feature that may assist in achieving a repeatable deployment in the presence of faults that may have reduced the capacity of the cloud is assigning priority to the containers such that mission critical components have the ability to evict less critical components. Kubernetes provides this capability with Pod Priority and Preemption. Prior to having more advanced production grade features available, the ability to at least be able to re-deploy ONAP (or a subset of) reliably provides a level of confidence that should an outage occur the system can be brought back on-line predictably.
Health Checks
Monitoring of ONAP components is configured in the agents within JSON files and stored in gerrit under the consul-agent-config, here is an example from the AAI model loader (aai-model-loader-health.json):
{
"service": {
"name": "A&AI Model Loader",
"checks": [
{
"id": "model-loader-process",
"name": "Model Loader Presence",
"script": "/consul/config/scripts/model-loader-script.sh",
"interval": "15s",
"timeout": "1s"
}
]
}
}
Liveness Probes
These liveness probes can simply check that a port is available, that a built-in health check is reporting good health, or that the Consul health check is positive. For example, to monitor the SDNC component has following liveness probe can be found in the SDNC DB deployment specification:
sdnc db liveness probe
livenessProbe:
exec:
command: ["mysqladmin", "ping"]
initialDelaySeconds: 30 periodSeconds: 10
timeoutSeconds: 5
The ‘initialDelaySeconds’ control the period of time between the readiness probe succeeding and the liveness probe starting. ‘periodSeconds’ and ‘timeoutSeconds’ control the actual operation of the probe. Note that containers are inherently ephemeral so the healing action destroys failed containers and any state information within it. To avoid a loss of state, a persistent volume should be used to store all data that needs to be persisted over the re-creation of a container. Persistent volumes have been created for the database components of each of the projects and the same technique can be used for all persistent state information.